Реактивная архитектура - это такая архитектура, которая построена по принципу обмена сообщениями.
Обмен сообщениями позволяет снизить зацепление между компонентами системы, что в свою очередь позволяет увеличить повторное использование, независимое тестирование и упростить взаимодействие компонентов системы.
Реактивная архитектуре - это не только удел микросервисных и event-драйвен систем, так же она реализуется в модульных монолитах, что позволяет в будущем гибко разводить архитектуру на отдельные самостоятельные компоненты.
В основе лежит четыре принципа, которые описаны в реактивном манифесте.
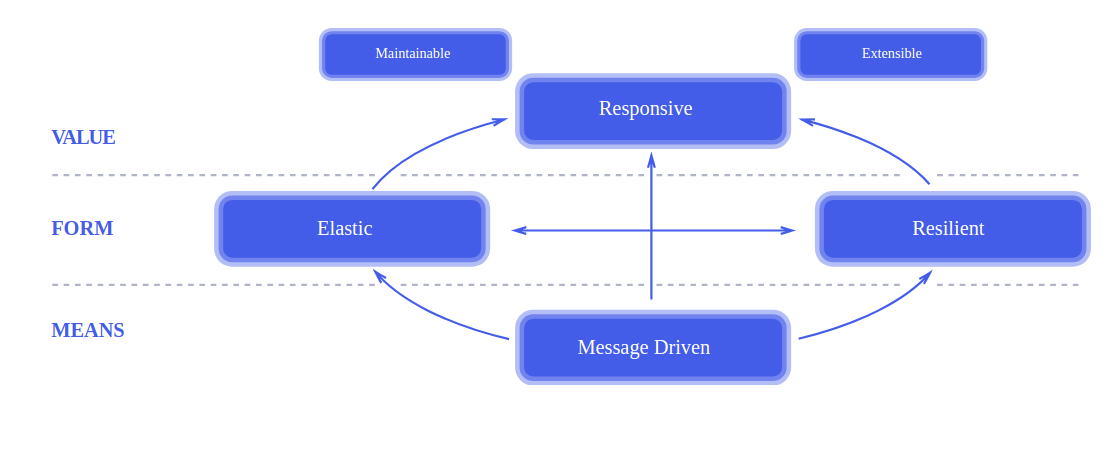
Основные концепции
- responsive (отзывчивость, доступность)
- resilent (отказоустойчивость)
- elastic (гибкий, масштабируемый)
- message-driven (обмен сообщениями)
Закон Амдала
Доступность
Приложения должны своевременно реагировать на запросы. При этом не обязательно выдерживать требования жесткого реального времени, мягкое с разумными границами тоже допустимо.
Отказоустойчивость
Приложения должны быть доступными, даже в случае сбоев. Механизмы достижения:
- дублирование
- контейниризация
- асинхронное делегирование
- мониторинг
- ресурсов
- логов
- действий пользователя, завершившихся сбоем (уровень бизнес-мониторинга)
Мониторинг должен строиться по принципу "достаточного запаса". Например, средняя нагрузка на сеть 50% - уже повод для добавления ресурсов.
Гибкость, масштабируемость
Балансировка нагрузки адаптированная под разные нагрузки, в архитектуре предусмотрены гибкие методы наращивания ресурсов
Механизмы достижения:
- вертикальное и горизонтальное масштабирование
Обмен сообщениями
- прозрачность местоположения
- неблокирующая обработка
- асинхронный обмен
Монолиты подразумевают прямой, транзакционный, синхронный способ обмена данными. Механика достижения ACID:
- Атомарность (Atomicity)
- Согласованность (Consistency)
- Изолированность (Isolation)
- Стойкость (Durability)
Реактивные архитектуры - это всегда eventual consistency (согласованность в конечном счете или возможность согласованности), для приближения к ACID используются компенсационные запросы (Compensating Transaction Pattern). Один из вариантов - Saga
Компенсационный запрос работает через
- хореографию (каждый слушает что делает другой и подстраивается и каждая транзакция публикует события, которые запускают транзакции в других сервисах.)
- оркестрация (кто-то один решает, другие подчиняются)
Основная проблема - нет стейта к которому можно откатиться. Так как стейтов несколько (у каждого сервиса свой), если компенсационная транзакция не прошла, то возникает вопрос - что делать?
Вариантов несколько, но они все плохие:
- повторить несколько раз
- уведомить мониторинг о проблеме
Упрощенный вариант взаимодействия. Напрмиер RxJS
- Сервисы - основная точка взаимодействия
- Снапшоты - источники стейта
- Очереди подписки: параметры и данные
- Компоненты - генерируют действия напрямую, реагируют асинхронно.
- Вьюшки - работают по MVVM модели
CQRS - Command Query Responsibility Segregation (разделение ответственности на команды и запросы)
CQRS - не значит, что надо использовать Event Sourcing (хранить не состояние, а набор действий по изменению стейта)
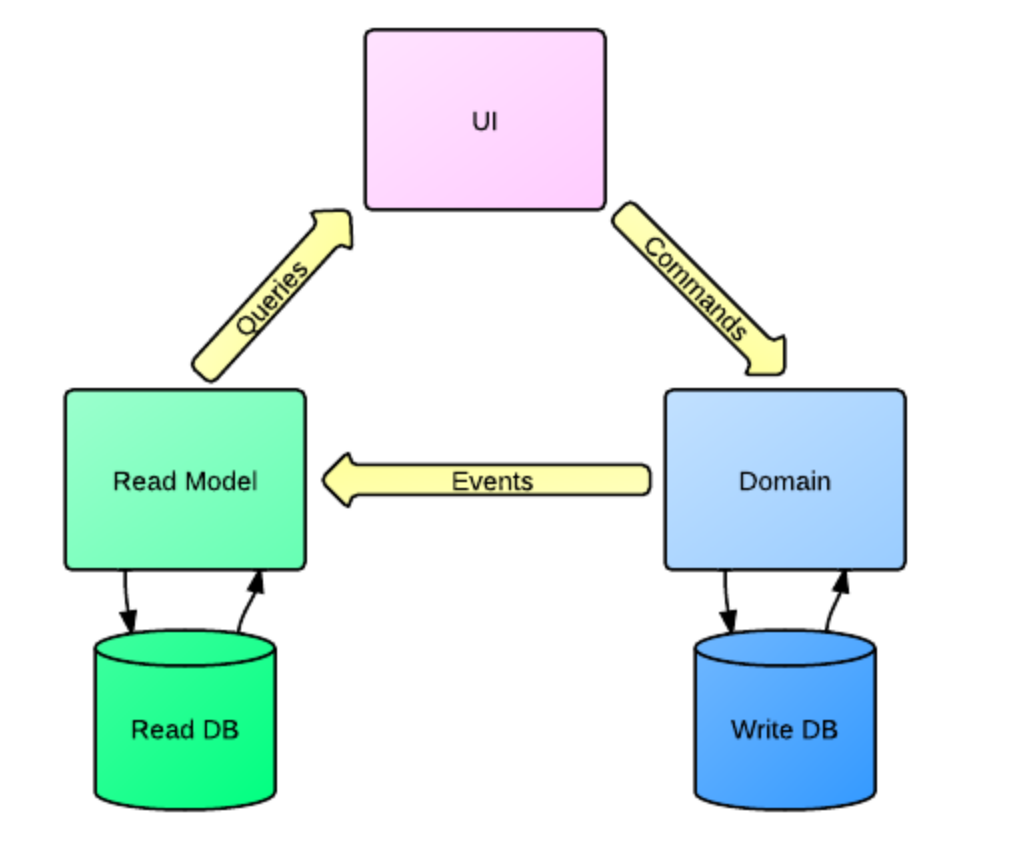
Вместо Event Sourcing можно использовать CQRS + saga
CQRS:
- Event Bus
- Command Bus | Query Bus
SAGA:
- commands
- compenstaions transtactions